
이 글은 혼자 공부하는 컴퓨터 구조+운영체제 교재와 강의를 참고하여 정리한 글입니다. 오타나, 잘못된 내용이 있으면 언제든지 알려주세요! 감사합니다.😊
보조기억장치
다양한 보조기억장치
보조기억장치는 전원이 꺼져도 저장된 내용을 잃지 않는 저장 장치이다.
가장 대중적인 보조기억장치는 하드 디스크와 플래시 메모리이다.
플래시 메모리는 USB 메모리, SD 카드, USB와 같은 저장 장치를 말한다.

하드 디스크
- 하드 디스크는 자기적인 방식으로 데이터를 저장하는 보조기억장치이다.
- 이러한 이유 때문에 하드 디스크를 자기 디스크의 일종으로 지칭하기도 한다.
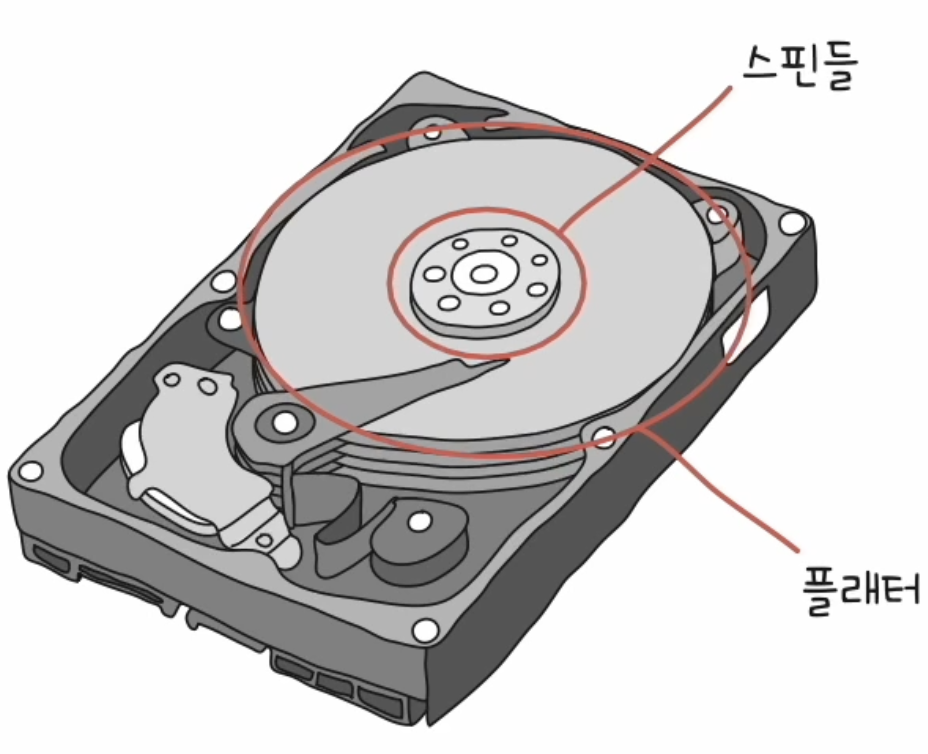
- 하드 디스크에서 실질적으로 데이터가 저장되는 곳은 동그란 원판이다. 이를 플래터라고 한다.
- 플래터는 자기 물질로 덮여 있어 수많은 N극과 S극을 저장한다.
- N극과 S극은 0과 1의 역할을 수행한다.
- 플래터를 여러 개를 사용할 수 있고, 일반적으로 플래터 양면을 모두 사용한다.
- 플래터를 회전시키는 구성 요소를 스핀들이라고 한다.
- 스핀들이 플래터를 돌리는 속도는 분당 회전수를 나타내는 RPM 단위로 표현된다.
- RPM (Revolution Per Minute)
- 예) 3,000 RPM이면 분당 3,000바퀴를 회전하는 하드 디스크이다.

- 플래터를 대상으로 데이터를 읽고 쓰는 구성 요소는 헤드이다.
- 헤드는 플래터 위에서 아주 미세하게 떠 있는 채로 데이터를 읽고 쓰는 부품이다. (바늘같이 생겼다)
- 일반적으로 모든 헤드가 원하는 위치로 헤드를 이동시키는 디스크 암에 부착되어 함께, 다 같이 이동한다.
- 면마다 헤드가 존재한다. 즉, 일반적으로 헤드의 수는 플래터의 수의 2배이다.
하드 디스크 저장 단위

- 플래터는 트랙과 섹터라는 단위로 데이터를 저장한다.
- 플래터를 여러 동심원으로 나누었을 때 그중 하나의 원을 트랙이라고 부른다. (운동장 달리기 트랙)
- 트랙은 마치 피자처럼 여러 조각으로 나누어지는데, 이 한 조각을 섹터라고 부른다.
- 섹터는 하드 디스크의 가장 작은 전송 단위이다.
- 섹터의 크기는 약 512 바이트 ~ 4096 바이트 정도의 크기를 가지고 있다. 하드 디스크에 따라 차이가 있다.
- 하나 이상의 섹터를 묶어 블록(block)이라고 표현하기도 한다.

- 여러 겹의 플래터가 사용될 수 있다고 했다.
- 여러 겹의 플래터 상에서 같은 트랙이 위치 한 곳을 모아 연결한 논리적 단위를 실린더라고 한다. (원통 모양)
- 즉, 플래터는 트랙과 섹터로 나뉘고, 같은 트랙이 모여 실린더를 이룬다.
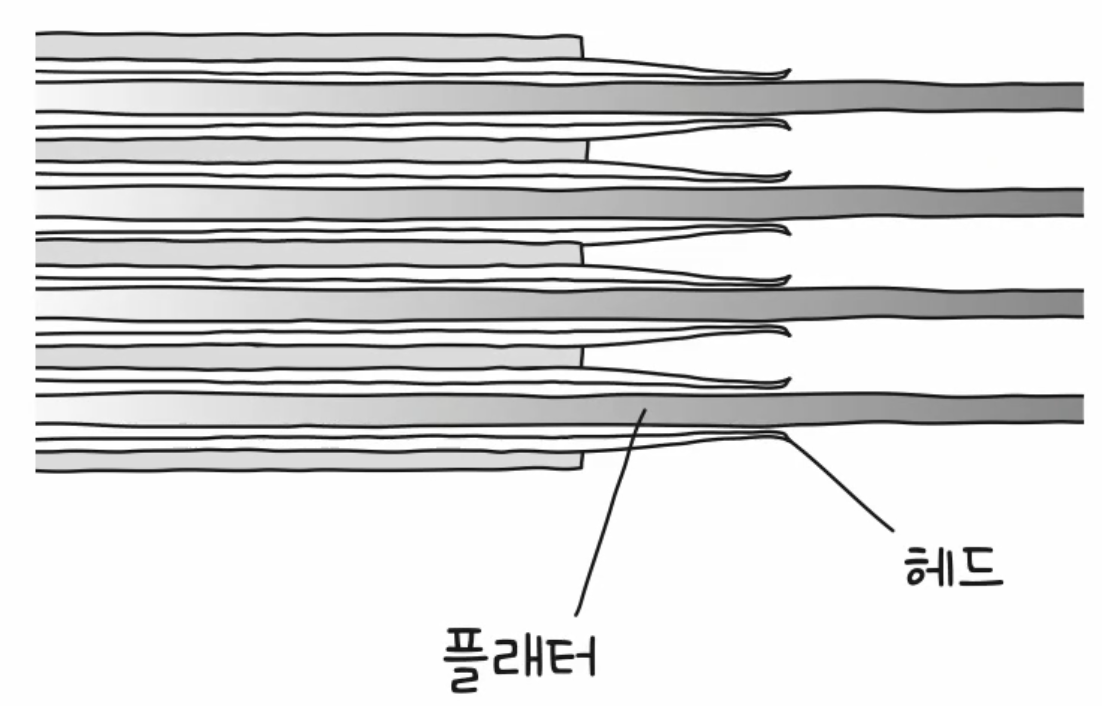
- 연속된 정보는 한 실린더에 기록된다.
- 예시)
- 두 개의 플래터를 사용하는 하드디스크에서 네 개의 섹터에 걸쳐 데이터를 저장해야 한다고 가정하자.
- 이럴 경우 첫 번째 플래터 윗면, 뒷면과 두 번째 윗면, 뒷면에 데이터를 저장한다.
- 연속된 정보를 하나의 실린더에 기록하는 이유는 디스크 암을 움직일 필요 없이 바로 데이터 접근이 가능하기 때문이다.
데이터가 하드 디스크의 섹터, 트랙, 실린더에 저장되는 것을 알았다.
그러면 하드디스크가 저장된 데이터에 접근하는 과정은 어떻게 될까?
하드 디스크 데이터 접근 과정
- 하드 디스크가 데이터에 접근하는 시간은 3개의 시간으로 이루어져 있다.
- 탐색 시간 (seek time)
- 회전 지연 (rotational latency)
- 전송 시간 (transfer time)
탐색 시간 (seek time)
- 탐색 시간은 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간을 의미한다.

회전 지연 (rotational latency)
- 회전 지연은 헤드가 있는 곳으로 플래터를 회전시키는 시간을 의미한다.

전송 시간 (transfer time)
- 전송 시간은 하드 디스크와 컴퓨터 간에 데이터를 전송하는 시간을 의미한다.

3가지 시간들은 성능에 큰 영향을 끼치는 시간들이다.
다음은 구글의 AI를 주도하고 있는 제프 딘이 공개한 '프로그래머가 꼭 알아야 할 컴퓨터 시간'의 일부이다.

- 생각보다 정말 많은 시간이 걸리는 것을 확인할 수 있다.
- 탐색 시간과 회전 지연을 단축시키기 위해서는 플래터를 빨리 돌려 RPM을 높이는 것도 중요하지만 참조 지역성, 즉 접근하려는 데이터가 플래터 혹은 헤드를 조금만 옮겨도 접근할 수 있는 곳에 위치해 있는 것도 중요하다.
참고: ns(나노 초)는 10-9초이다. 패킷은 네트워크의 기본적인 전송 단위이다.
참고: 플래터의 한 면당 헤드가 하나씩 달려 있는 하드 디스크를 단일 헤드 디스크라 부르며, 헤드가 트랙별로 여러 개가 달려있는 하드디스크를 다중 헤드 디스크라고 부른다. 다중 헤드 디스크는 트랙마다 헤드가 있어 탐색 시간이 0이다.
이러한 점에서 헤드를 움직일 필요가 없는 다중 헤드 디스크를 고정 헤드 디스크라고 부르며, 헤드를 데이터가 있는 곳까지 움직여야 하는 단일 헤드 디스크를 이동 헤드 디스크라 부른다.
플래시 메모리
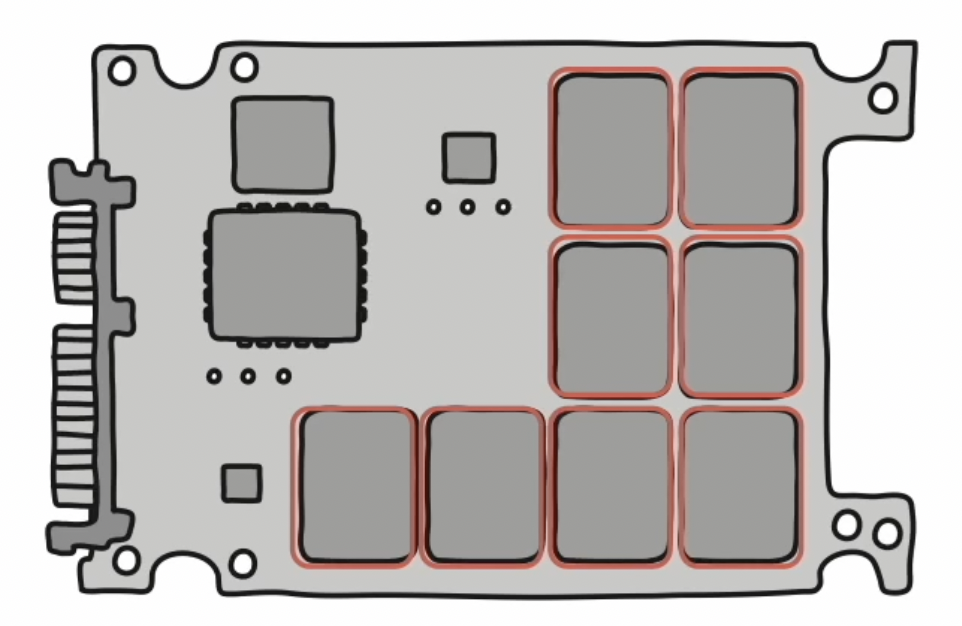
- 플래시 메모리는 전기적으로 데이터를 읽고 쓸 수 있는 반도체 기반의 저장 장치이다.
- USB 메모리, SD 카드, SSD가 모두 플래시 메모리 기반의 보조기억장치이다.
- 범용성이 넓기에 보조기억장치 범주에만 속한 다기보다는 다양한 곳에서 널리 사용하는 저장 장치로 보는 것이 맞다.
- 주기억장치 중 하나인 ROM에도 사용된다.
플래시 메모리의 종류에는 크게 두 가지가 존재한다.
- NAND 플래시 메모리
- NAND 연산을 수행하는 회로(NAND 게이트)를 기반으로 만들어진 메모리이다.
- 대용량 저장 장치로 많이 사용되는 플래시 메모리이다.
- NOR 플래시 메모리
- NOR 연산을 수행하는(NOR 게이트)를 기반으로 만들어진 메모리이다.
셀 (cell)
- 플래시 메모리에서 데이터를 저장하는 가장 작은 단위이다.
- 이 셀이 모이고 모여 MB, GB, TB 용량을 갖는 저장 장치가 된다.
하나의 셀에 몇 비트를 저장할 수 있느냐에 따라 플래시 메모리 종류가 나뉜다.
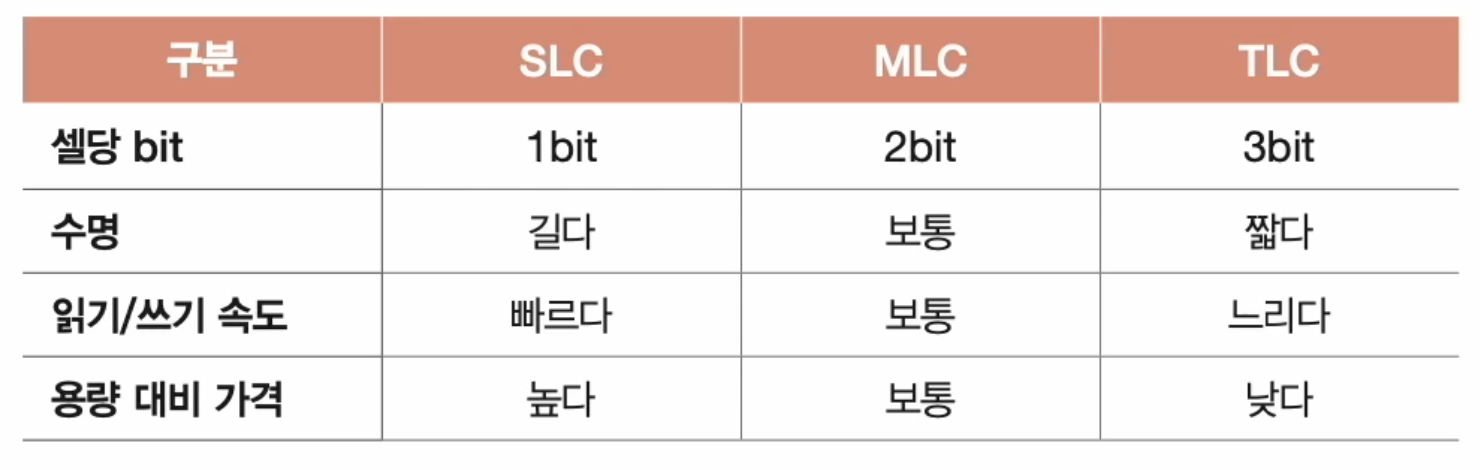
- 한 셀에 1비트를 저장할 수 있는 플래시 메모리: SLC
- 한 셀에 2비트를 저장할 수 있는 플래시 메모리: MLC
- 한 셀에 3비트를 저장할 수 있는 플래시 메모리: TLC
- 한 셀에 4비트를 저장할 수 있는 플래시 메모리: QLC
- 이는 플래시 메모리의 수명, 속도, 가격에 큰 영향을 끼친다.
참고: 플래시 메모리(USB, SSD, SD 카드)에도 수명이 존재하고, 하드 디스크 또한 수명이 존재한다. 한 셀에 일정 횟수 이상 데이터를 쓰고 지우면 그 셀은 더 이상 데이터를 저장할 수 없기 때문이다.
예시) 종이에 연필로 쓰고 지우개로 지우는 작업을 반복하면 그 종이는 못쓰게 된다.
플래시 메모리 SLC, MLC, TLC
세 타입의 특징과 차이점을 더 쉽게 알아보기 위해 다음과 같이 비유를 들어보자.
사람 한 명을 1비트, 셀을 집에 비유한다고 하면 다음과 같이 이해할 수 있다.
- SLC는 한 집에 한 명
- MLC는 한 집에 두 명
- TLC는 한 집에 세 명
SLC 타입

- 한 셀로 두 개의 정보를 표현할 수 있다.
- 비트의 빠른 입출력이 가능하다.
- 수명이 조금 더 길지만, 용량 대비 가격이 높다.
- 혼자 자취하는 게 같이 사는 것보다 비용이 더 많이 드는 것과 같다.
- 데이터를 읽고 쓰기가 매우 많이 반복되며 고성능의 빠른 저장 장치가 필요한 경우에 사용한다.
MLC 타입

- 한 셀로 네 개의 정보를 표현할 수 있다. 즉 대용량 화하기 유리하다.
- SLC보다 입출력이 느리고, 수명이 짧지만 SLC보다 저렴하다.
- 시중에서 많이 사용된다. (MLC, TLC, QLC)
TLC 타입

- 한 셀로 여덟 개의 정보를 표현할 수 있다. 즉 MLC와 마찬가지로 대용량화하기 유리하다.
- MLC보다 입출력이 느리고, 수명이 짧지만 MLC보다 저렴하다.
- 시중에서 많이 사용된다. (MLC, TLC, QLC)
같은 플래시 메모리라도 수명, 가격, 성능이 다르다는 것을 알 수 있다.
썼다 지우기를 자주 반복해야 하는 경우나 높은 성능을 원하는 경우네는 고가의 SLC 타입을 선택하자.
저가의 대용량 장치를 원한다면 TLC 타입, 그 중간을 원한다면 MLC 타입의 저장 장치를 선택하자.
플래시 메모리에는 셀이라는 단위가 있다고 존재하고, 이 셀이 모이고 모여 MB, GB, TB 저장 장치가 된다고 했다.
가장 작은 단위인 셀보다 더 큰 단위를 알아보자.

- 셀들이 모여 페이지(page)가 된다.
- 페이지들이 모여 블록(block)이 된다.
- 블록이 모여 플레인(plane)이 된다.
- 플레인이 모여 다이(die)가 된다.
플래시 메모리에서 읽기/쓰기 단위와 삭제 단위는 다르다.
플래시 메모리의 가장 큰 특징 중 하나이다.
- 읽기와 쓰기는 페이지 단위로 이루어진다.
- 삭제는 페이지보다 큰 블록 단위로 이루어진다.
페이지의 상태
페이지는 세 개의 상태를 가질 수 있다.
- Free 상태
- 어떠한 데이터도 저장하고 있지 않아, 새로운 데이터를 저장할 수 있는 상태를 말한다.
- Valid 상태
- 이미 유효한 데이터를 저장하고 있는 상태를 말한다.
- Invalid 상태
- 유효하지 않은 데이터(쓰레기값)를 저장하고 있는 상태를 말한다.
- 플래시 메모리는 하드 디스크와 달리 덮어쓰기가 불가능하기 때문에, Valid 상태인 페이지에는 새 데이터를 저장할 수 없다.
플래시 메모리의 동작을 예시로 알아보자.

- 블록 X가 네 개의 페이지로 이루어져 있다고 가정하자. 그리고 그중 두 개의 페이지에는 A와 B라는 데이터가 저장되어 있다.
- 만약 블록 X에 새로운 데이터 C를 저장하면 어떻게 될까?
- 플래시 메모리의 읽기 쓰기 단위는 페이지라고 했다. 따라서 왼쪽 아래칸에 데이터 C가 저장된다.
근데 여기서 데이터 B와 C는 그대로 둔 채 기존의 A를 A'로 수정하고 싶다고 하면 어떻게 해야 할까?
삭제는 페이지보다 큰 블록 단위로 이루어진다고 했다. 따라서 A를 삭제할 수는 없다.

- A를 Invalid 페이지로 만든 다음에, A'를 새로운 페이지에 저장해 준다.
- A는 Invalid 상태가 되어 더 이상 유효하지 않은 쓰레기 값이 되고, Valid 페이지는 B, C, A'가 된다.
- 근데 A와 같이 쓰레기값을 저장하고 있는 공간은 사용하지 않음에도 용량을 차지하고 있다. 즉, 용량 낭비인 것이다.
- 이러한 쓰레기값을 정리하기 위해 가비지 컬렉션(garbage collection) 기능을 제공한다.
- 가비지 컬렉션은 valid, 유효한 페이지들만을 새로운 블록으로 복사한다.
- 그 후 기존의 블록을 삭제하는 기능이다.
- 즉, 가비지 컬렉션은 valid, 유효한 페이지들만 새로운 블록으로 복사한 후 기존 블록을 삭제하여 공간을 정리하는 기능이다.
RAID의 정의와 종류
1TB 하드 디스크 네 개와 4TB 하드 디스크 한 개중 어떻게 사용하는 것이 더 나을까?
1TB 하드 디스크 네 개로 RAID를 구성하면 4TB 하드 디스크 한 개의 성능과 안전성을 능가할 수 있다.
RAID의 정의
정보량이 어마어마하고, 민감한 정보들을 어떻게 안전하게 관리할까? 보조기억장치에도 수명이 있다고 했다.
이럴 때 사용할 수 있는 방법 중 하나가 RAID이다.
- RAID(Redundant Array of Independent Disks)는 하드 디스크와 SSD를 사용하는 기술이다.
- 데이터의 안전성 혹은 높은 성능을 위해 여러 물리적 보조기억장치를 마치 하나의 논리적 보조기억장치처럼 사용하는 기술이다.
RAID의 종류
RAID의 종류는 RAID 레벨이라고 한다.
RAID 레벨
- RAID 레벨은 RAID를 구성하는 기술이다.
- 대표적으로 RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6
- 그로부터 파생된 RAID 10, RAID 50 등이 있다.
- RAID 10은 RAID 0과 RAID 1을 혼합한 방식이다.
- RAID 50은 RAID 0과 RAID 5를 혼합한 방식이다.
참고: 현재는 RAID 2와 RAID 3은 잘 활용되지 않는다.
참고: RAID 레벨을 혼합한 방식을 Nested RAID라고 한다.
가장 대중적인 RAID 0, RAID 1, RAID 4, RAID 5, RAID 6에 대해 알아보자.
RAID 0

- RAID 0은 데이터를 단순히 나누어 저장하는 구성 방식이다.
- 1TB 하드 디스크 네 개로 RAID 0을 구성했다고 가정하자.

- 어떠한 데이터를 저장할 때 각 하드 디스크는 번갈아 가며 데이터를 저장한다.
- 즉, 저장되는 데이터가 하드 디스크 개수만큼 나뉘어 저장되는 것이다.
- 마치 줄무늬처럼 분산되어 저장된 데이터를 스트라입이라고 하며, 분산하여 저장하는 것을 스트라이핑이라 한다.
그럼 RAID 0는 어떤 장점과 단점이 있을까? 번갈아가면서 저장하는 이유는 뭘까?

- RAID 0는 입출력 속도가 빠르다는 장점이 있다.
- 스트라이핑 되면, 즉 데이터가 분산되어 저장되면 저장된 데이터를 읽고 쓰는 속도가 빨라진다.
- 하나의 대용량 저장 장치를 이용했다면 여러 번에 걸쳐 읽고 썼을 데이터를 동시에 읽고 쓸 수 있기 때문이다.

- RAID 0는 저장된 정보가 안전하지 않다는 단점이 있다.
- 만약 하드디스크 하나가 문제가 생긴다면 다른 모든 하드 디스크의 정보를 읽는데 문제가 발생한다.
이러한 문제점을 해결하기 위해 RAID 1이 등장하게 되었다.
RAID 1
- RAID 1은 복사본을 만드는 방식이다.
- 마치 거울처럼 완전한 복사본을 만드는 구성이기에 미러링(mirroring)이라고도 부른다.

- 데이터를 쓸 때 원본과 복사본 두 군에 써서, 쓰기 속도는 느리다.
- RAID1 장점: 복구가 매우 간단하다. 문제가 발생해도 잃어버린 정보를 금방 되찾을 수 있다.
- RAID1 단점: 하드 디스크 개수가 한정되었을 때 사용 가능한 용량이 적어지는 단점이 있다.
- 예시) RAID 0에서는 4TB의 정보를 저장할 수 있지만, RAID 1에서는 2TB의 정보만 저장할 수 있다.
- 즉, RAID 1에서는 복사본이 만들어지는 용량만큼 사용자가 사용하지 못한다.
RAID 4

- RAID 4는 RAID 1처럼 완전한 복사본을 만드는 대신, 오류를 검출하고 복구하기 위한 정보를 저장한 장치를 두는 구성 방식이다.
- 오류를 검출하고 복구하기 위한 정보를 패리티 비트(parity bit)라 한다.
- RAID 4에서는 패리티를 저장한 장치를 이용해 다른 장치들의 오류를 검출하고, 오류가 있다면 복구한다.
- RAID 1보다 적은 하드 디스크로도 데이터를 안전하게 보관할 수 있다.
참고: 원래 패리티 비트는 오류 검출만 가능할 뿐 오류 복구는 불가능하다. 하지만 RAID에서는 패리티 값으로 오류 수정도 가능하다. RAID 4에서는 패리티 정보를 저장한 장치로써 나머지 장치들의 오류를 검출하고 복구한다.
패리티 비트는 본래 오류 검출용 정보지만, RAID에서는 오류 복구도 가능하다.

- RAID 4에서는 어떤 새로운 데이터가 저장될 때마다 패리티를 저장하는 디스크에도 데이터를 쓰게 되므로 패리티를 저장하는 장치, 패리티 디스크에 병목 현상이 발생하는 문제가 있다.
- 병목현상이란 시스템의 성능이 지연되고 프로세스 전체적인 효율성이 감소되는 것이다.
이러한 병목 현상 문제를 해소하기 위해 RAID 5 방식을 사용한다.
RAID 5

- RAID 5는 패리티 정보를 분산하여 저장하는 방식이다.
즉, RAID 4는 패리티를 저장한 장치를 따로 두는 방식이고, RAID 5는 패리티를 분산하여 저장하는 방식이다.
RAID 6

- RAID 6의 구성은 기본적으로 RAID 5와 같으나, 서로 다른 두 개의 패리티를 두는 방식이다.
- 즉, 오류를 검출하고 복구할 수 있는 수단이 두 개인 것이다.
- RAID 4와 RAID 5보다 안전한 구성이라고 볼 수 있다.
- 하지만, 새로운 정보를 저장할 때마다 함께 저장할 패리티가 두 개이기 때문에 쓰기 속도는 RAID5보다 느리다.
- 데이터 저장 속도를 감수하더라도 데이터를 더욱 안전하게 보관하고 싶을 때 사용하는 방식이다.
각 RAID 레벨마다 장단점이 있다. 어떤 상황에서 무엇을 최우선으로 원하는지에 따라 최적의 RAID 레벨이 달라진다. 즉, 각 RAID 레벨의 구성과 특징을 아는 것이 중요하다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 입출력장치 (0) | 2023.04.22 |
|---|---|
| [컴퓨터 구조] 메모리와 캐시 메모리 (1) | 2023.04.14 |
| [컴퓨터 구조] CPU의 성능 향상 기법 (0) | 2023.04.12 |
| [컴퓨터 구조] CPU의 작동 원리 (0) | 2023.04.06 |
| [컴퓨터 구조] 명령어 (1) | 2023.04.02 |